🌸はじめに
こんにちは。私は入社以来、ソフトウェアエンジニアの部隊で働いています。
前回「
サービス維持を見据えたモノづくり!〜見えない仕組みが価値を支える〜」では、システムの安定運用に関わるシステムの裏側の考え方をご紹介しました。
今回は、ちょっと具体的なお話と、それに関連してオープンソースプロジェクト「
OpenTelemetry」について解説できればと思います。
🕵探偵ってかっこいい
まずは身の上話です。私が入社した当時、ある先輩にお世話になりました。その先輩は、「探偵になりたくてソフトウェアエンジニアになったんだ」と言っていました。障害やトラブルが起きたときに原因を突き止めて、「犯人はお前だ!」と特定するわけです。
確かに、真っ先に問題を解決する探偵はかっこいいですね。また、問題解析というと憂鬱になるかもしれませんが、仕事も謎解き気分で楽しめたらいいですね!
さて、犯人を見つけるには「手がかり」が必要です。
システム開発でも、トラブルが起きたときに備えて手がかりを残す仕組みを作ることが大切です。
🌱サービス維持に必要なもの
サービスを維持していくため、起こった問題で早急に「犯人」を見つけること、そのためには「手がかり」となる情報をシステムとして記録しておく必要があります。
たとえば、通販サイトを作り上げたとして
・問題:「買いものしていたのに途中でエラーになっちゃった😫」。
手がかり:サーバーのエラーをログとして残しましょう
・問題:「なんだかサイトの応答が遅いな🤔」。
手がかり:レスポンスタイムや処理時間を測定しましょう
・問題:「商品検索、もっと早く表示されないかな😗」。
手がかり:ボトルネック箇所を特定できるように、システムのコンポーネントでかかる時間を測定しましょう
このようにトラブルを解決するために、手がかりとなる情報を記録することが、サービス維持には必要です。
とはいえ、全ての情報を記録しておくことはできません。
どんな情報を残すか取捨選択があり、企業ごとにノウハウや経験が生きるポイントでもあります。また、こういった手がかりを残す機能の作り込みは、時間もお金もかかってきます。
🔭OpenTelemetryってなんだろう
OpenTelemetryは、アプリケーションからログ、トレース、メトリクスといった観測データを統一的に収集・出力するためのフレームワークです。
用語の詳しい説明は別途調べていただくとして(そのときは、オブザーバビリティというキーワードでも調べてみてください)、これらはすべて「犯人を知るための手がかり」です。ログ、トレース、メトリクスは、どれか一つだけではなく、複数を組み合わせることで効果を発揮します。たとえるなら、警備員の巡回、監視カメラも設置、人感センサ―の配備など、多角的な監視体制を作るイメージです。
しかし、厳重にすることはそれだけ開発コストがかかります。
これらの仕組みを作るコストに値するのは、複数のコンポーネントやサービスが繋がってシステムを構成するような複雑なシステム(マイクロサービス)などに限られていました。
しかし、OpenTelemetryとして仕様を統一され、ライブラリも充実し、またAWSなどのクラウドサービスも連携できる環境ができてきたので、比較的簡単に導入できるようになりました。
👮事件です
では、OpenTelemetryでどんな手掛かりがみられるか、どうやって犯人を突き止めるかを見てみたいと思います。
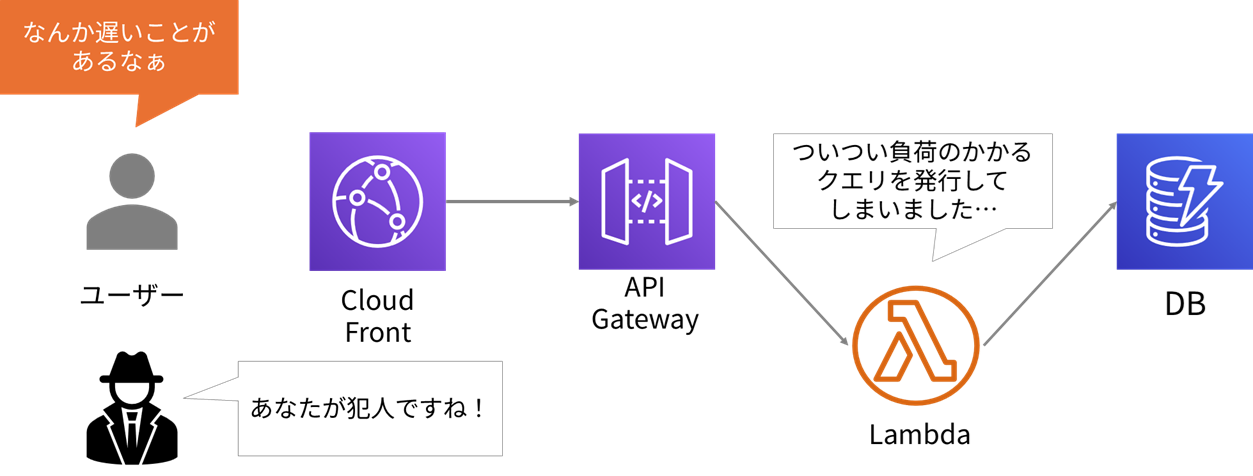
ある日、AWS上に構築したシステムで事件が起きました。ユーザーからのリクエストに対する応答が遅くなることがあるといったものでした。
原因はどこにあるのでしょう?
関連するシステムの構成は以下のようになっています。
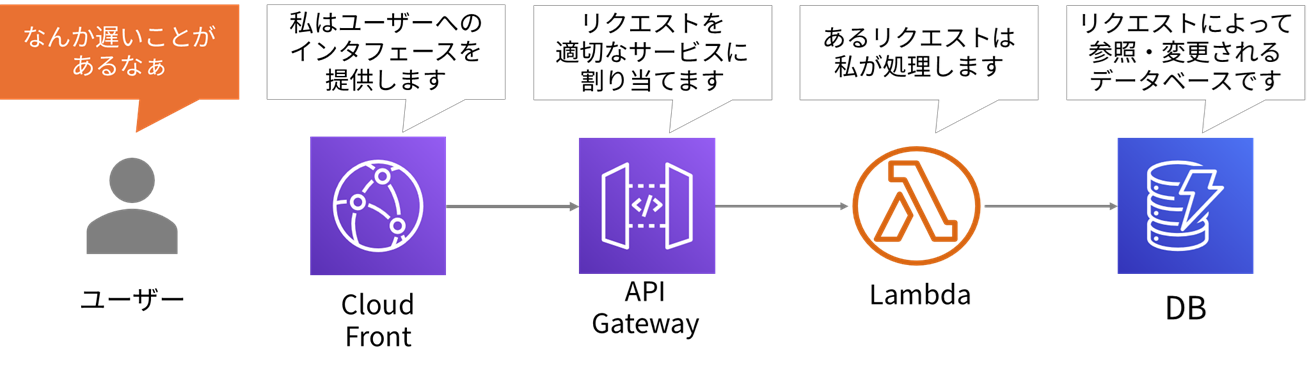
📜ログからわからないこともある
まずは各コンポーネントのエラーを確認しましょう。記録されたログを使って聞き込みを行います。なにかおかしなこと(エラー)はありませんでしたか?
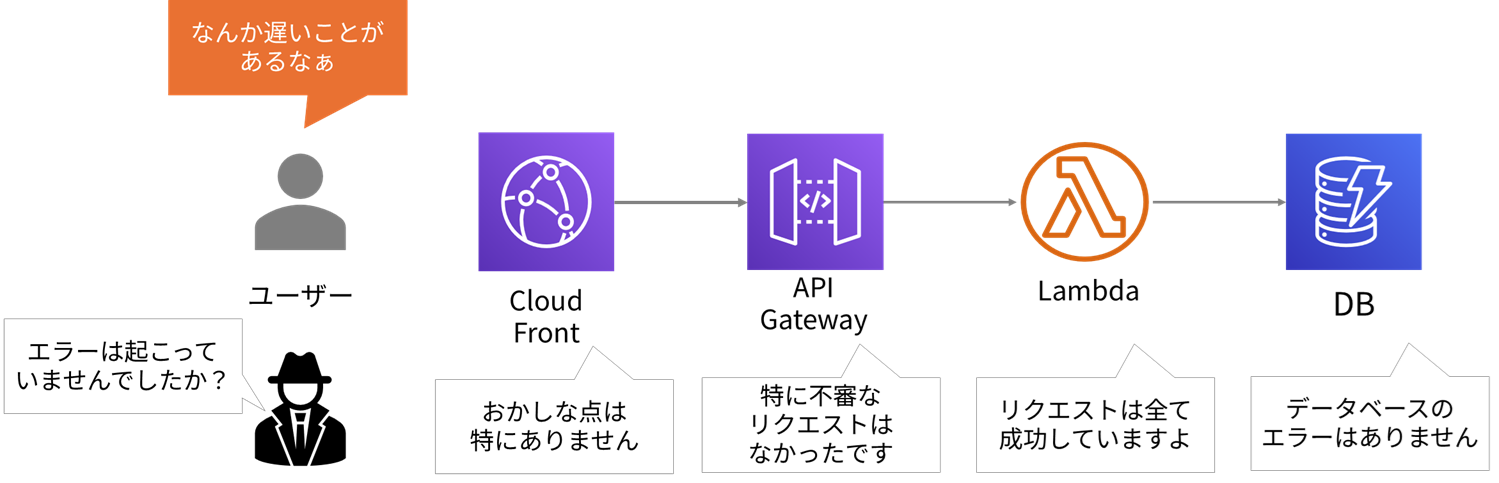
特におかしい点はないみたいですね。エラーの有無だけでは原因が特定できないケースもあります。それでは、トレースを見ることにしましょう。
👣トレースで犯人を追いかけよう!
トレースというのは、サービスがリクエスト毎にIDを割り振り、そのリクエストの処理の流れや各コンポーネントでかかった時間を追跡できる仕組みです。API Gatewayはこのトレースに対応しているので、手がかりを持っているはずです。聞いてみましょう。
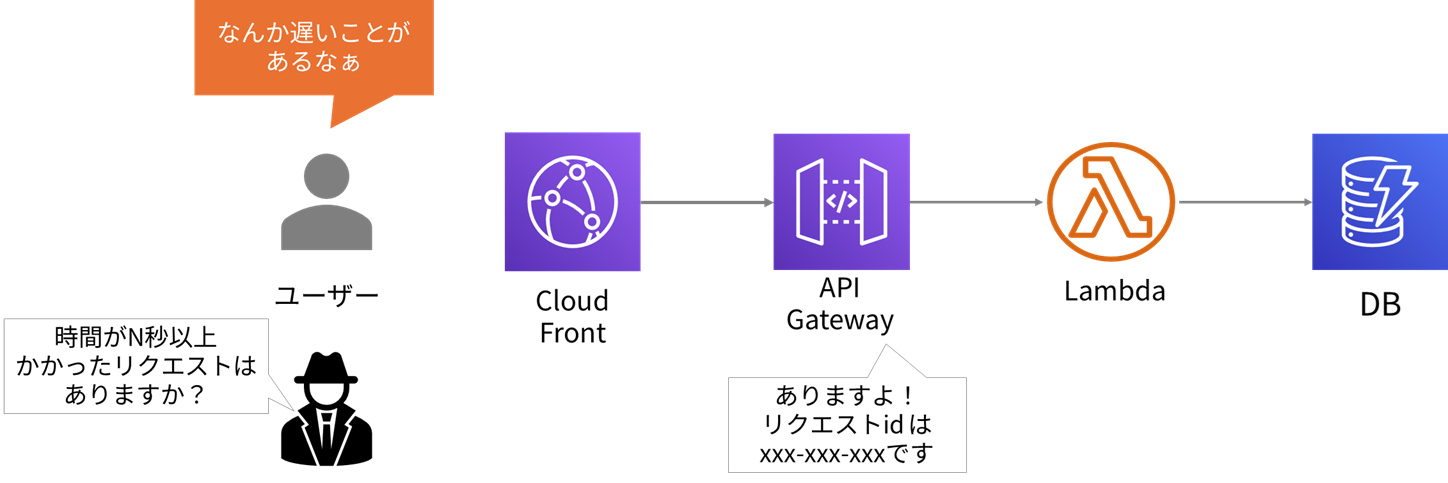
遅いリクエストがあったようですね。それでは、何が起こっていたのか、トレースで追いかけてみましょう。
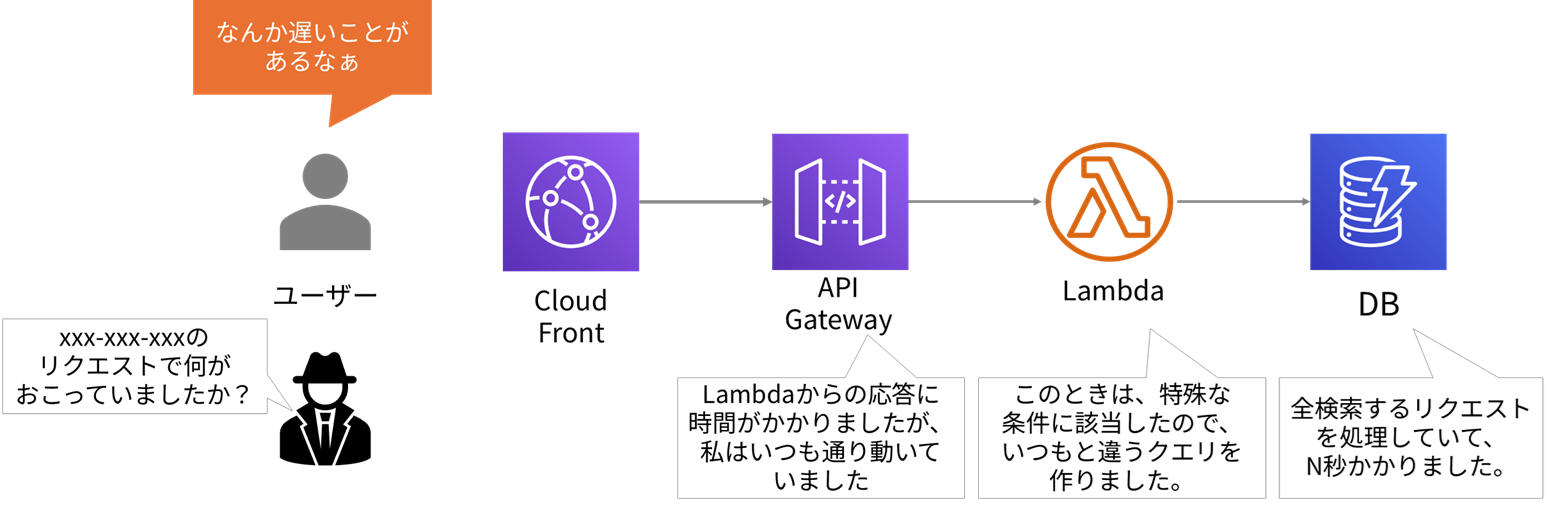
Lambdaさんが、怪しいですね!
🔍犯人はお前だ!
Lambdaさんに聞きとり調査です。
遅くなったリクエストの詳細や、Lambdaが実行していたクエリ内容、なぜその処理になったかをログで確認します。
すると、ある特定の条件のときは、DBの全件検索という重い処理を発行してしまうことが分かりました。このせいで時間がかかっていたのですね。DBが突発的に遅くなることもあるのですが、今回はLambdaのコンポーネントが重たいクエリ(DBに対するリクエスト)を発行していたことが要因でした。DBの構成を見直したり、クエリを工夫したりして解決する必要がありそうですが、ともかく犯人を見つけることができ、原因を放置せずに済みました。
📄トレースって実際どんなもの
実際のトレース画面では、どのサービスがあって、それぞれ個別のリクエストに対してどのくらい時間がかかったかが表示されます。
AWSでは、Lambdaに数行のコードを追加し、各種サービスでOpenTelemetryを有効にするだけでこういった情報が見られるようになります。
これだけ手軽なら、ぜひ使ってみたいですね!
🌄おわりに
今回は、サービス維持にあたって必要な、問題の早期発見について解説しました。また、そのための仕組み作りとしてOpenTelemetryを活用できることも紹介しました。
ポイントは、このような仕組みを素早く取り入れることができるようになったことです。実際のソフトウェア開発においては、このように保守性も考えた、サービス維持を見据えたモノづくり!が必要になってきます。
他にも、どのような機能を検討していく必要があるか、もし機会があればお話ししていきたいと思います。ここまでお読みいただきありがとうございました。
2026年3月
株式会社 日立情報通信エンジニアリング
エンジニアリング事業部 第1本部 第3部 中村 圭記
※編集・執筆当時の記事のため、現在の情報と異なる場合があります。編集・執筆の時期については、記事末尾をご覧ください。
